dbt (data build tool) is an open-source framework that lets data teams transform raw warehouse data into analytics-ready tables using SQL. It applies software engineering practices, version control, testing, modularity, and documentation, to the transformation step of the modern data stack. Today, more than 40,000 companies use dbt in production, including Nasdaq, Siemens, HubSpot, and McDonald's Nordics.
This guide covers the essentials, the recent shifts, and where dbt fits in your stack.
1. What is dbt?
dbt stands for "data build tool." It's a transformation framework that sits on top of your cloud data warehouse like Snowflake, BigQuery, Databricks, Redshift, Microsoft Fabric, Postgres, etc, and lets you build, test, and document data models using SQL SELECT statements.
Crucially, dbt doesn't move or store data itself. It handles the T in ELT (Extract, Load, Transform): it takes the code you write, compiles it into raw SQL, and tells your warehouse to execute that SQL. Your data never leaves the warehouse.
Today, dbt is one of the leading standards for analytics engineering and is looking to enforce that position even more after announcing a definitive merger agreement with Fivetran in October 2025.
2. How does dbt work?
At a mechanical level, dbt has two jobs: compile and run.
You write SQL SELECT statements (called models) in your text editor or IDE. dbt compiles those statements, resolving Jinja templates, references between models, and configuration, into raw SQL. Then it executes that SQL against your warehouse, materializing the results as tables, views, incremental tables, or ephemeral CTEs.
Here's what a typical dbt project contains:
- Models: SQL files (or Python files for advanced cases) that define each transformation step.
- YAML config files: declare model properties, tests, sources, and documentation. If you want a deeper walkthrough of project setup, our guide on dbt YAML configuration covers dbt_project.yml and profiles.yml in detail.
- Tests: assertions that catch broken data (nulls, duplicates, referential integrity) before it reaches a dashboard.
- Seeds: small static CSV files (lookup tables, country codes) loaded into the warehouse with dbt seed.
- Snapshots: point-in-time captures of slowly changing dimensions.
- Macros: reusable Jinja-templated SQL blocks (think: functions for SQL).
When you run dbt build, dbt figures out the dependency graph between your models, which one depends on which, and executes them in the right order. It also auto-generates a lineage graph showing exactly how raw source data flows through to your final reporting tables.
This is why teams care: instead of dozens of brittle, ad-hoc SQL scripts scattered across notebooks and warehouse UIs, you get a single, version-controlled, tested, documented codebase that produces your analytics layer.
3. Exploring the dbt platform: core components
As of 2026, there are effectively three things to understand about dbt: dbt Core, the dbt platform (formerly called dbt Cloud), and the new dbt Fusion engine.
For a full comparison, check out this deep-dive. But let’s unpack the high-level differences here too…
dbt Core
dbt Core is the free, open-source command-line tool, written in Python and licensed under Apache 2.0. You install it on your laptop, a CI runner, or a server, point it at your warehouse, and run commands like dbt run, dbt test, and dbt docs generate. It's the foundation everything else is built on, and dbt Labs has committed to keeping it open source under its current license.
The trade-off: Core gives you full control, but you handle scheduling, orchestration (typically with Airflow or Dagster), CI/CD, secrets management, and developer environments yourself.
dbt Cloud (now "the dbt platform")
dbt Platform is dbt Labs' commercial managed offering. It bundles a browser-based IDE, job scheduling, hosted documentation, CI/CD integration, monitoring, alerting, and enterprise governance features (RBAC, audit logs, semantic layer, dbt Mesh). dbt Labs has rebranded dbt Cloud to "the dbt platform" to reflect that it now supports multiple engines underneath, both dbt Core and Fusion.
For teams without a dedicated platform-engineering crew, the platform removes the hosting and orchestration burden. Pricing starts at the Pro tier and scales to Enterprise, with costs that depend on developer seats and successful job runs.
dbt Fusion engine
This is the big new shiny product of dbt. The dbt Fusion engine is a ground-up rewrite of dbt's execution engine in Rust, launched in public beta on May 28, 2025.
Why it matters? Three reasons:
- Speed. Fusion parses and compiles dbt projects up to 30× faster than dbt Core, according to dbt Labs' product page. On large projects (5,000+ models), parsing drops from minutes to seconds.
- SQL comprehension. Fusion is a true SQL compiler. It understands the meaning of your SQL, not just the templated string. That enables real-time error detection, autocomplete, hover info, and column-level lineage in the new VS Code extension.
- State-aware orchestration. Fusion fingerprints code, config, and upstream data state. When something changes, it rebuilds only the models actually affected, cutting warehouse compute costs significantly.
Fusion uses the same authoring layer as dbt Core (same SQL, same Jinja, same YAML), so existing projects can migrate without rewriting models. As of early 2026, Fusion is available locally for free, in the dbt platform (private preview), and through the official dbt VS Code extension.
4. Where dbt fits in the data stack
dbt is purpose-built for the ELT pattern: load raw data into a cloud warehouse first, then transform it inside the warehouse. It's not an ETL tool, doesn't extract data from sources, and doesn't load data. It's the transformation layer that sits between ingestion and analytics.
A typical 2026 stack looks like this:
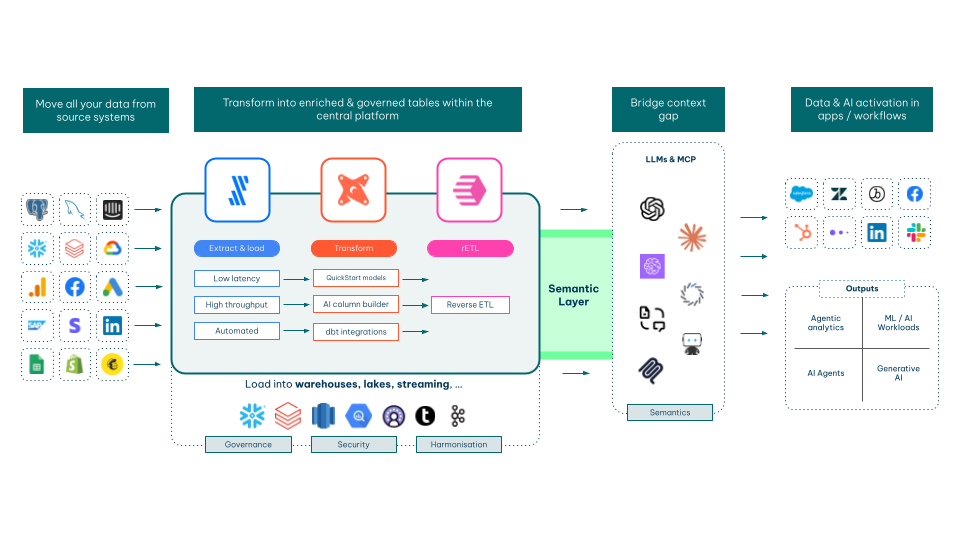
Ingestion: Fivetran, Airbyte, or Stitch pulls data from SaaS sources, databases, and event streams into your warehouse.
Storage & compute: Snowflake, BigQuery, Databricks, Redshift, or an open table format like Apache Iceberg.
Transformation: dbt models the raw data into clean, tested, documented analytics tables.
Semantic Layer: can sit on different layers within this architecture. But essentially, it is where you bridge the context gap between your central data layer, and LLMs used for AI activation.
BI & AI activation: Tableau, Power BI, Looker, or ThoughtSpot for visualization; reverse ETL tools push modeled data back into operational systems. AI activation with agents, agentic workflows, etc.
5. Why teams use dbt: 5 core benefits
Five concrete reasons dbt has become the standard:
- Modular, reusable SQL. Break complex pipelines into small, named models. Reference them with {{ ref('model_name') }} and dbt handles dependency resolution. Change a model once, and every downstream consumer gets the update.
- Built-in testing. Generic tests (unique, not_null, accepted_values, relationships) catch data quality problems automatically. You can also write custom SQL or unit tests. Testing is one of the fastest ways to improve data quality across the organization.
- Auto-generated documentation and lineage. dbt produces an interactive docs site showing every model, its description, its columns, its tests, and a clickable DAG of how data flows through your project, without anyone manually writing it.
- Version control by default. Because dbt projects are just code in a Git repo, every change goes through pull requests, code review, and CI. You get a full audit trail of who changed what, when, and why.
- Warehouse-native execution. dbt pushes transformation work down to the warehouse engine you already pay for. There's no separate compute cluster to maintain, no data movement, no duplication.
dbt: Frequently Asked Questions
What does dbt stand for?
dbt stands for "data build tool." The acronym is always lowercase in official branding. It started as an internal project at RJMetrics in 2016 and is now developed by dbt Labs (formerly Fishtown Analytics).
Is dbt an ETL or ELT tool?
dbt is an ELT tool — specifically, it handles the "T" (Transform) step. It assumes your data has already been extracted and loaded into a cloud data warehouse, and it transforms that data using SQL executed inside the warehouse. dbt does not extract data from source systems and does not load data into the warehouse.
What's the difference between dbt Core and dbt Cloud?
dbt Core is the free, open-source command-line tool you self-host; dbt Cloud (now called the dbt platform) is dbt Labs' commercial managed service that adds a browser IDE, job scheduling, hosted documentation, CI/CD, and enterprise features on top of Core. Core gives you full control and zero license cost; the platform removes the operational overhead and is the recommended path for most teams without dedicated platform engineers.
What is the dbt Fusion engine?
The dbt Fusion engine is a Rust-based rewrite of dbt's execution engine, released in public beta in May 2025. It compiles and parses dbt projects up to 30× faster than the Python-based dbt Core, understands SQL natively (enabling autocomplete, inline errors, and column-level lineage), and supports state-aware orchestration that rebuilds only the models actually affected by a change. Fusion uses the same authoring layer as dbt Core, so most existing projects can migrate without rewriting models.
Summary
dbt has become the standard transformation layer of the modern data stack because it does one thing exceptionally well: it lets data teams apply software engineering rigor — version control, testing, documentation, modularity — to analytics workflows, while running entirely inside the warehouse you already use.
The next 18 months will reshape the dbt ecosystem more than any period since 2016. The Fusion engine brings a step-change in performance and developer experience, and the pending merger with Fivetran will likely consolidate ingestion and transformation into a single, more tightly integrated platform. If your team is evaluating dbt, or already running it and looking to adopt Fusion or rethink your modern data stack, Biztory's dbt expertise can help you scope, deploy, and scale.