



A modern semantic layer is a governed, shared language between your business and your data. It's a single place where metrics, dimensions, and business rules are defined once and reused everywhere, from BI dashboards to AI agents.
It matters because without one, the same question returns different answers in different tools, and AI assistants confidently produce numbers that contradict the finance report. In 2026, with AI making metric drift faster and more expensive, the semantic layer has shifted from a nice-to-have BI feature to the foundation of trustworthy analytics.
Let's dig deeper!
What Is a Modern Semantic Layer?
A semantic layer is a governed translation layer between raw data and the people (and systems) that consume it. It defines, in business terms, what a "customer" is, how "ARR" is calculated, and which filters constitute an "active contract", then enforces those definitions consistently across every tool that touches the data.
In practice, a usable semantic layer contains six things:
- Business-friendly names and descriptions for key entities (customers, orders, subscriptions)
- Metrics and their measures: for example, Churn Rate = churn_amount / starting_arr
- Dimensions and hierarchies: Region → Country → State; Calendar → Fiscal Month → Quarter
- Time intelligence: trailing windows, cumulative totals, period-over-period comparisons
- Lineage, ownership, certification, and policy (row- and column-level security) that travel with the definition
- Interfaces for reuse: SQL, notebooks, dashboards, and increasingly AI agents
When this is in place, three outcomes follow. Teams share a common language with named, owned metrics that everyone recognises. Reuse becomes the default. The same definition powers a BI dashboard, a Python notebook, and a conversational AI agent. And change gets safer, because updates propagate through governed channels instead of being copy-pasted between SQL editors.
Why the Semantic Layer Matters More Than Ever in the AI Era
The semantic layer is not a new idea. What's new is the cost of going without one.
Two forces have changed the maths. First, BI tool sprawl: 61% of enterprises now use four or more BI platforms, according to Forrester.
Each platform brings its own modelling language and its own version of the truth. Second, AI. Large language models do not apply human judgement when they encounter conflicting definitions, they pick one and answer confidently. A dashboard can tolerate ambiguity. An AI agent amplifies it into misinformation that's much harder to audit after the fact.
The data on this is striking. Research cited by AtScale shows that organisations using a semantic layer cut analytics project costs by 50% and complete projects four times faster. On the AI side, Google's internal testing of Looker's semantic layer found it reduced data errors in generative AI natural language queries by as much as two-thirds. Other studies suggest semantic layers make AI responses up to three times more accurate compared to direct SQL queries against ungoverned data.
For data leaders, this maps to a real strategic problem: decision debt. Every undefined metric is interest accruing on every future decision. The longer ambiguity persists, the harder it becomes to introduce AI safely, because each new agent inherits the cracks already in the foundation.
This is also why semantic layers and data governance are now inseparable conversations. Definitions without governance drift.
Governance without definitions has nothing to enforce.
Why Yesterday's Semantic Layers Break Under Today's Workloads
Every previous generation solved the problem in front of it. Universes made SQL-heavy schemas legible. Cubes governed calculations at scale. LookML gave analysts speed. Headless layers tried to knit fragmented tools back together.
Six things break when those approaches meet 2026 workloads:
1. Scale and speed no one planned for. Early universes and cubes were designed for overnight refreshes. Today's queries can scan billions of rows and users expect answers in seconds. Aggregate tables and cube schedules become brittle workarounds when data is always changing.
2. Too many versions of the truth. A universe definition here, a cube there, LookML in one tool, DAX in another. Each may be internally consistent, but across tools the cracks show. Two teams ask the same question and get different numbers... not because the maths is wrong, but because the definitions diverged.
3. Semantics trapped in tool silos. DAX in Power BI, LookML in Looker, VizQL in Tableau, MDX in cubes. Powerful innovations, but each tied semantics to a single surface. Data scientists, operational apps, and AI agents sit outside, unable to reuse those definitions.
4. Governance reinvented in every tool. Security and lineage belong with the data. When semantics live outside the platform, row-level security gets reimplemented in each tool. Auditors, analysts, and AI agents all face the same question: which rules actually apply?
5. Performance patched, not shared. Each tool builds its own caches and extracts. They work locally but multiply globally. Keeping dozens of disconnected caches in sync with the warehouse becomes its own operations problem.
6. Not built for AI. None of the earlier semantic layers were designed with large language models in mind. LLMs need more than a metric definition, they need synonyms, explanations, and guardrails. A dashboard tolerates ambiguity; an AI agent amplifies it into hallucination. When semantic models live outside the platform, disconnected from governance and lineage, agents inherit those cracks.
Zoom out and you see the pattern. Each generation solved the problems it could see, but always from the outside in. Semantics were bound to the tool, not the platform. That worked when BI meant a single reporting system. In a world of cloud platforms, multi-tool ecosystems, and agentic analytics, it isn't enough.
Where Should the Semantic Layer Sit?
Once you accept that scattered definitions are the problem, the question becomes architectural: where does the semantic layer actually live?
In its Redefining the Modern Semantic Layer white paper, Databricks frames three options on a maturity curve: good, better, best.
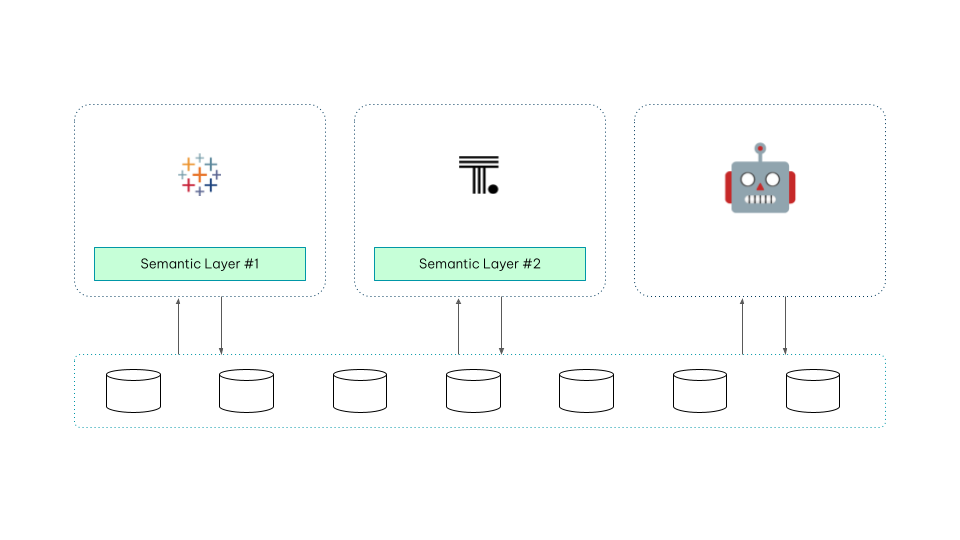
Option 1: Siloed semantic layers (good). Each BI tool maintains its own model: Definitions are governed within a tool but diverge across tools. This is where most enterprises still are, and it's why the same question returns different numbers on different dashboards.
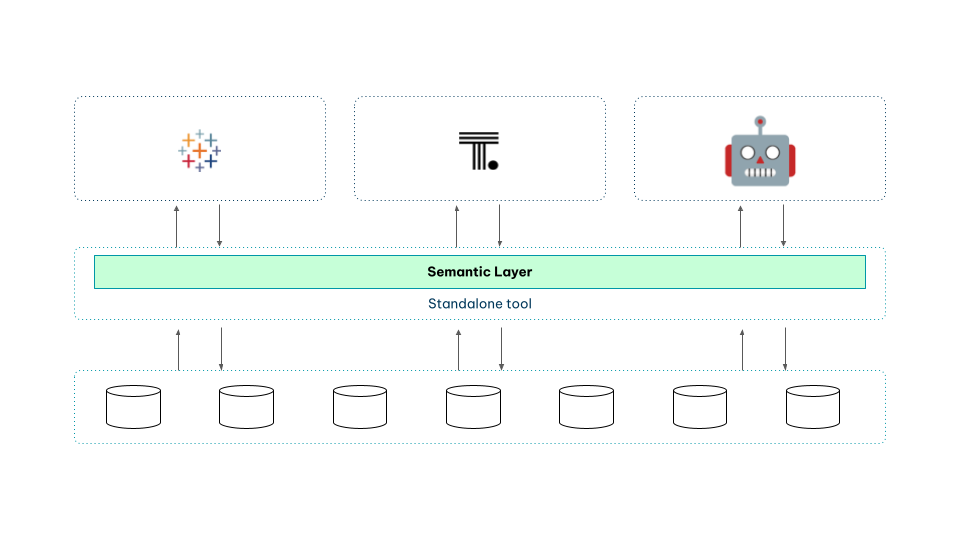
Option 2: Universal semantic layer (better). A headless, tool-agnostic layer (Atlan, dbt Semantic Layer, ...) sits between the data platform and the consuming tools, serving definitions via SQL, REST, and JDBC. One definition, many consumers — a real improvement.
But the semantic layer is now a separate system to govern, secure, and keep in sync with the data platform underneath it. Governance and lineage live in two places.
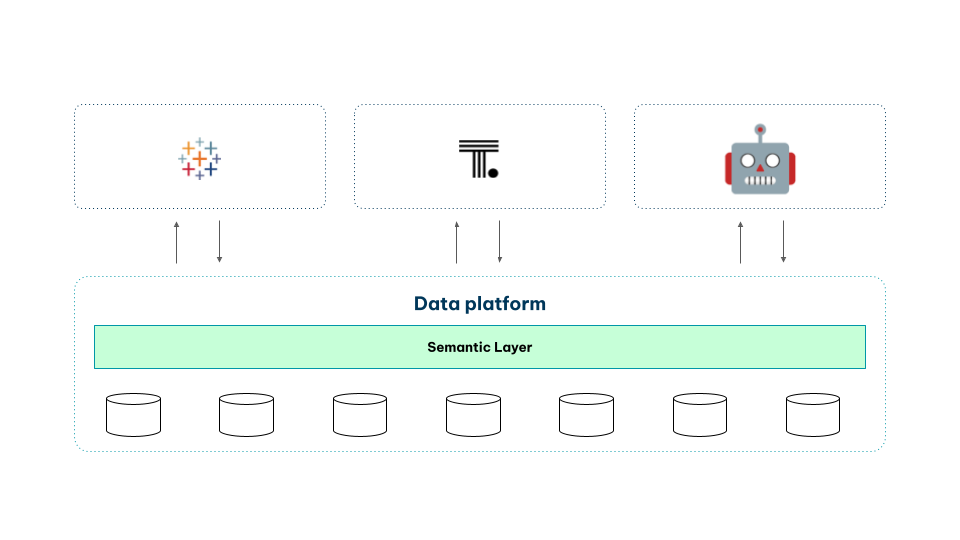
Option 3: Unified semantic layer (best). Semantics live inside the data platform itself, next to the data, policies, lineage, and audit logs, then project outward to every tool and agent. Definitions inherit row- and column-level security automatically. Lineage is automatic. Certification is a first-class signal both humans and AI agents can trust. There's one system to govern, not two.
The unified model is what Databricks calls platform-native semantics. The clearest current example is Databricks Unity Catalog Business Semantics, which combines metric views (governed measures and dimensions exposed through SQL) with agent metadata (the synonyms, descriptions, and guardrails AI agents need to interpret questions correctly).
A measure defined once is consumable from SQL editors, BI tools like Tableau Next and Power BI, notebooks, and AI agents like Databricks Genie, all returning the same governed answer. Snowflake's Semantic Views and Cortex Analyst follow the same logic at the warehouse layer.
The industry is converging on a single idea: semantics belong with data, not bolted onto the tools that consume it.
Frequently Asked Questions
What is a semantic layer in data analytics?
A semantic layer is a governed translation layer that sits between raw data and the tools that consume it. It defines business metrics, dimensions, joins, and rules in one place, so every BI tool, notebook, and AI agent calculates "revenue" or "active customers" the same way. Modern semantic layers also carry governance — lineage, ownership, and access policies — alongside the definitions.
Why do traditional semantic layers fail for AI?
Traditional semantic layers were built for human-driven BI, where some ambiguity is tolerable. They live inside individual tools (DAX in Power BI, LookML in Looker), use proprietary languages, and lack the context AI needs; synonyms, explanations, and guardrails. When AI agents query data without grounded semantics, they pick one of several conflicting definitions and answer confidently, producing hallucinations that are hard to audit.
How does a semantic layer reduce AI hallucinations?
A semantic layer reduces AI hallucinations by replacing guesswork with governed definitions at query time. Instead of an agent inferring what "ARR" means from raw column names, it queries an approved metric with the right filters, joins, and time logic already encoded. Google's testing of Looker's semantic layer found this approach cut data errors in natural language queries by up to two-thirds, and other research has shown AI responses up to three times more accurate when grounded in semantic definitions versus direct SQL.
What's the difference between a semantic layer and a data catalog?
A data catalog documents what data exists, where it lives, who owns it, what columns it has, how it was produced. A semantic layer defines what data means and enforces that meaning at query time. The two are complementary: the catalog tells you the asset exists; the semantic layer makes sure every consumer calculates it the same way. Modern platforms like Databricks Unity Catalog combine both functions in a single governed layer.
Is a platform-native semantic layer better than a universal one?
It depends on your architecture. A platform-native semantic layer (Databricks Unity Catalog, Snowflake Semantic Views) is the strongest choice when most of your data and AI workloads run on a single data platform. It offers the tightest governance, lineage, and performance integration. A universal/headless layer (Atlan, dbt Semantic Layer, etc) is better suited to polyglot environments with multiple warehouses or many BI tools. For most enterprises consolidating onto a modern lakehouse, the platform-native approach is becoming the default.
Conclusion
The semantic layer has been with us for thirty years, but its job description has changed. What started as a way to simplify SQL for analysts has become the foundation of trustworthy AI. The waves of universes, cubes, code, and headless layers all chased the same goal — a shared language for data — and all bumped against the same wall: semantics that live outside the platform fragment governance, duplicate effort, and leave AI agents to guess.
The modern answer is to put semantics where data, policies, and lineage already live: inside the data platform itself. That's the principle behind platform-native semantics, and it's why Databricks Unity Catalog, Snowflake Semantic Views, and similar approaches are reshaping the architecture discussion in 2026.
Source: Databricks white paper | Redefining the semantic layer




