



A modern data stack for AI is a centralised, cloud-native infrastructure that covers five layers — ingestion, centralisation, transformation, semantic modeling, and activation — structured so that AI agents and LLMs can query trusted, governed data without hallucinating. Without it, even the most powerful AI model produces unreliable answers.
This guide walks through each step so your organisation can stop patching legacy pipelines and start building a foundation that makes AI actually work.
Why 75% of AI initiatives fail — and it's not the model
Three numbers tell the story before we even get to architecture.
75% of corporate AI initiatives fail. 62% of data systems are not fully ready to leverage AI. 64% of organisations find integrating data sources for AI genuinely challenging. These statistics — from Fortune, Salesforce, and Snowflake respectively — point to the same root cause: the data foundation is not ready.
The failure is almost never the model. GPT-4, Claude, Gemini — these are extraordinarily capable systems. The failure is what sits behind them. Fragmented data sources, inconsistent metric definitions, siloed storage, and a total absence of business context mean that even the best AI produces answers nobody can trust.
The good news is that this is an infrastructure problem, not an intelligence problem. It is entirely solvable — if you approach it in the right sequence.
The problem: data fragmentation is the real AI bottleneck
Most organisations' data estates look like a sprawling diagram of disconnected parts: warehouses here, data lakes there, pipelines stitched together by different teams using different code bases, BI tools sitting on top of their own siloed definitions. There is no single source of truth. There is no shared business language.
This fragmentation creates four compounding problems.
Data silos create brittle pipelines and inconsistent governance. When the same metric is calculated differently in your CRM, your finance warehouse, and your marketing dashboard, every AI query that touches those systems becomes a gamble.
Rising cost and complexity blocks scalability. Multiple copies of data, consumption-based pricing across disconnected platforms, and maintenance overhead that demands expensive engineering resources — all of this compounds with every new data source you add.
No metadata foundation means no context for AI. This is the critical one. If you point an LLM at a raw data warehouse and ask "How did our online sales perform last quarter?", the model has no idea which tables to use, whether "online" includes mobile app orders, whether "sales" nets off returns, or whether you mean calendar or fiscal quarter. Missing context is not a minor inconvenience. It is the reason AI gives wrong answers confidently.
AI activation is impossible without a semantic foundation. Agentic analytics, AI agents in business workflows, conversational BI — none of these work reliably until the data layer speaks the same language as the business.
The solution is not to buy a new AI tool. It is to build a modern data stack that makes your data AI-ready from the ground up.
Step 1: Data Ingestion
The first step is getting your data moving — reliably, automatically, and at scale.
Data ingestion is the process of extracting data from your source systems (databases, SaaS applications, files, event collectors, marketing and finance platforms) and loading it into a destination where it can be worked with. The challenge is that most organisations are sitting on a patchwork of approaches that were never designed to work together.
Legacy ETL pipelines are expensive to build, highly manual, and not designed for the performance demands of modern AI workloads. DIY ingestion scripts — often written by individual engineers to solve immediate problems — accumulate into a maintenance nightmare: different owners, different code bases, low governance, and no consistency. Streaming infrastructure solves the wrong problem for most data movement; not every pipeline needs real-time replication, and adding that complexity for batch use cases is wasteful.
Modern ELT tools like Fivetran and Rivery resolve these issues. They connect to 300+ data sources via pre-built, fully managed connectors, support both structured and unstructured data, handle log-based CDC replication automatically, and include built-in compliance controls for GDPR, CCPA, and HIPAA. Data extractions include both historical loads and incremental updates, and automated recovery from failure means pipelines stay healthy without manual intervention.
The output of this step is raw data — arriving consistently, governed from the start, and ready to be centralised.
Step 2: Centralisation
With data flowing in from your sources, the next step is bringing it together into a single, scalable platform where it can be governed, queried, and built upon.
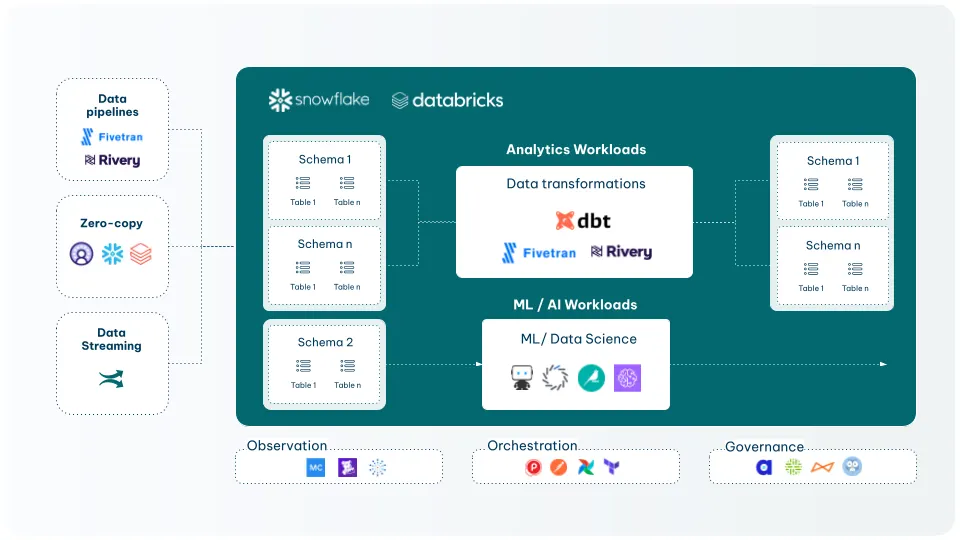
Centralisation ends the knowledge silos that come from fragmented storage. When different teams own different databases with no shared foundation, you get limited business visibility, an inability to see the big picture, and a lack of any coherent data strategy.
Centralised data inverts all of that: unified and harmonised datasets, reduced maintenance overhead, increased visibility across key data assets, and — critically — the platform consistency that AI at scale requires.
Snowflake and Databricks are the dominant platforms for this layer. Both provide scalable cloud-native storage for structured and unstructured data, support zero-copy data sharing, and offer the AI infrastructure — generative AI, machine learning workloads, container runtimes — that sits on top of a well-governed data foundation.
Centralisation is also where governance, security, and harmonisation become structural rather than aspirational. Role-based access controls, data lineage, and schema management are built into the platform from the start — not retrofitted later when an audit demands them.
This is the foundation everything else depends on. A semantic layer built on fragmented data is still fragmented. An AI agent querying ungoverned data is still unreliable. Centralisation is the prerequisite.
Step 3: Transformation & Modeling
Raw centralised data is not AI-ready. It needs to be cleaned, structured, enriched, and modeled before it can reliably serve analytics or AI workloads.
dbt (data build tool) has become the standard for data transformation in the cloud warehouse. It brings software engineering discipline — version control, testing, documentation, lineage — to what was previously a collection of ad hoc SQL scripts owned by different people with different conventions.
For AI specifically, dbt delivers a couple of things that matter enormously...
Integrity: Built-in data assertions catch inconsistencies before they propagate downstream to AI agents. If a model breaks, you find out in the pipeline — not in a hallucinated answer surfaced to a business user.
Governance: End-to-end lineage across workflows, projects, and teams means you can trace any metric back to its source. For regulated industries and auditability requirements, this is non-negotiable.
Documentation: dbt makes it possible to describe your data in business-readable terms directly alongside the code that defines it. That documentation becomes the context layer AI systems need to reason correctly.
Development integration: Transformations live in version control, go through code review, and deploy via CI/CD. The data pipeline becomes as reliable as the software that runs your product.
The output of this step is transformed, enriched, and governed tables — the structured foundation that AI agents, BI tools, and ML workloads can all draw from with confidence.
Step 4: Semantics
This is the step that most organisations skip — and the single biggest reason their AI projects produce inconsistent, untrustworthy outputs.
A semantic layer is a business-readable translation layer that sits between your data platform and your consumers — BI tools, AI agents, LLMs. It defines what your metrics mean, how they are calculated, and how the underlying tables relate to each other, in terms that both humans and AI systems can understand.
Without it, the same question gets different answers depending on where you ask it. Ask one BI tool "What is our Annual Recurring Revenue?" and it might return €2.5M. Ask another connected to a different model and it might return €2.4M. Ask an AI agent directly and it might invent a calculation from scratch.
The problem is not the tools. It is the absence of a shared definition.
There is a spectrum of approaches, from good to best.
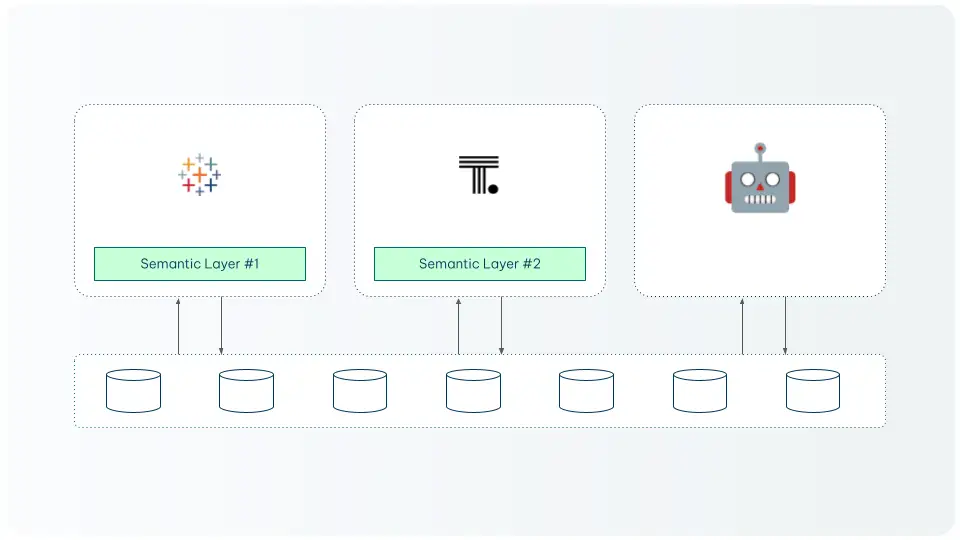
Good: A siloed semantic layer
Where each BI tool or application defines metrics independently — is better than nothing but creates exactly the inconsistency problem described above. When you add AI agents into this setup, they have no way to know which definition is authoritative.
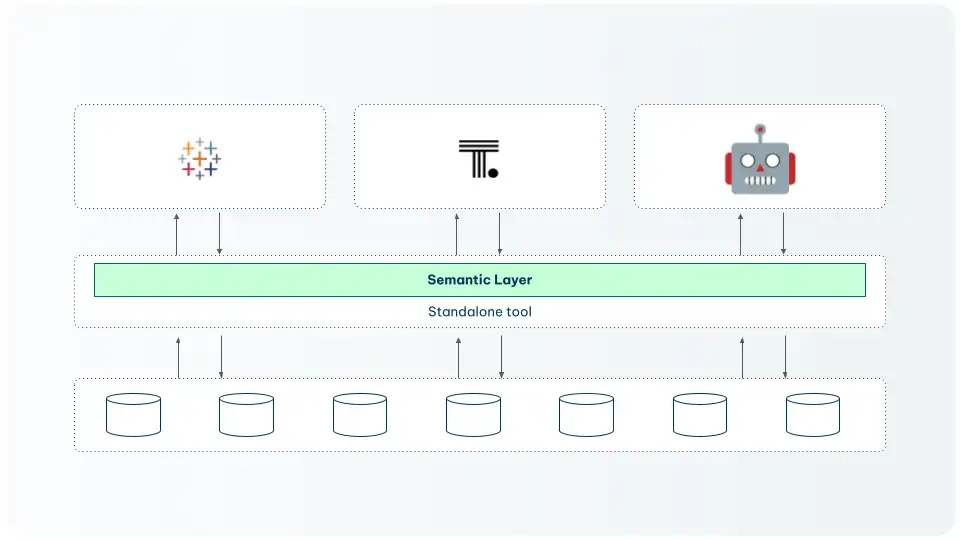
Better: A universal semantic layer
A standalone tool that all consumers connect to — is significantly better. Every tool reads from the same source of truth. But it adds an extra layer of infrastructure to maintain and can create integration complexity as the number of consumers grows.
Best: A unified semantic layer
Built directly into the data platform — is the gold standard. Semantic definitions live in the warehouse, governed alongside the data, and exposed to every consumer including LLMs via MCP (Model Context Protocol).
The dbt Semantic Layer combined with Snowflake's native semantic views represents this architecture in practice.
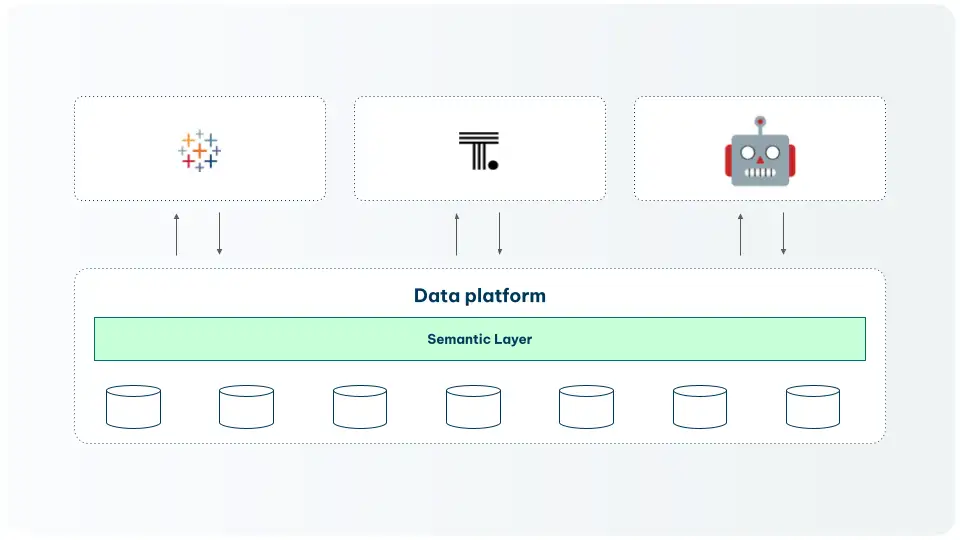
With a unified semantic layer in place, an AI agent querying your data has access to models, metrics, lineage, freshness signals, and ownership metadata. It knows what tables to use, how to compute your KPIs correctly, and which definitions are production-trusted.
That is the difference between an AI that guesses and one that answers reliably.
Step 5: BI & AI Activation
With clean, centralised, transformed, and semantically governed data, you are ready to activate it. The question is: what level of activation are you building toward?
Business intelligence has been evolving through three distinct phases, and understanding where you sit on this spectrum shapes what you build next.
Traditional BI is reactive, manual, and fragmented. Periodic data extracts, one-off models locked inside the BI layer, every new question requiring a data analyst in the loop. Insights stop at the dashboard — they do not automatically become actions.
Augmented BI introduces AI-powered helpers: forecasting, anomaly detection, and natural language query interfaces. But it is still dashboard-bound. The AI is faster at answering questions, but it is answering the same limited set of questions from within the same siloed tools.
Agentic BI is the destination. Agents with deep knowledge of the entire data landscape, unified semantics accessible across tools and workflows, continuous monitoring and signal detection, and the ability to act on insights autonomously without requiring a human analyst for every question. An agent does not just tell you that revenue dropped 12% last week. It identifies the cause, escalates to the right person, and triggers a response workflow.
This is not a distant future state. It is available today for organisations that have built the five-layer foundation described in this guide. The full activation stack gives you the complete, AI-ready architecture.
Frequently Asked Questions
What is a modern data stack for AI?
A modern data stack for AI is a cloud-native data infrastructure built across five operational layers: data ingestion, centralisation, transformation and modeling, semantic layer, and BI and AI activation. Unlike a traditional data stack focused purely on reporting, an AI-ready stack is structured so that LLMs, AI agents, and automated workflows can query trusted, governed, contextually rich data to produce reliable answers at scale.
Why do most corporate AI initiatives fail?
75% of corporate AI initiatives fail primarily because of data infrastructure problems, not model limitations. The most common causes are fragmented data sources that produce inconsistent outputs, the absence of a semantic layer that gives AI the business context it needs, poor data governance that allows metric definitions to drift across tools, and the inability to integrate data sources in a way that creates a reliable single source of truth. Fixing the data foundation — not switching AI models — is what unlocks consistent results.
What is a semantic layer and why does AI need it?
A semantic layer is a business-readable translation layer that defines what your metrics mean, how they are calculated, and how your data tables relate to one another. AI systems need it because LLMs have no inherent knowledge of your business definitions — without one, they guess which tables to query and how to calculate KPIs, producing inconsistent or hallucinated results. A unified semantic layer, such as the dbt Semantic Layer connected to Snowflake's Cortex, gives AI agents deterministic, governed definitions they can rely on.
What is agentic BI?
Agentic BI is the most advanced phase of business intelligence, where AI agents with deep knowledge of the entire data landscape can monitor data continuously, detect signals, and act on insights autonomously — without requiring a human analyst in the loop for every question. It differs from augmented BI (which adds AI helpers to traditional dashboards) by combining a unified semantic layer with agentic workflows, enabling the system to not just answer questions but trigger responses across business systems.



.webp)
