How Snowflake Works
Snowflake's architecture is designed to separate storage and compute, which enables users to scale each independently. Data is stored in a central data repository, and queries are processed using virtual warehouses, which are composed of multiple compute nodes.
These virtual warehouses can be scaled up or down on-demand, providing users with the ability to scale their compute resources as needed. Snowflake's unique architecture also allows for workload isolation, preventing resource contention and enabling users to scale only what is needed.
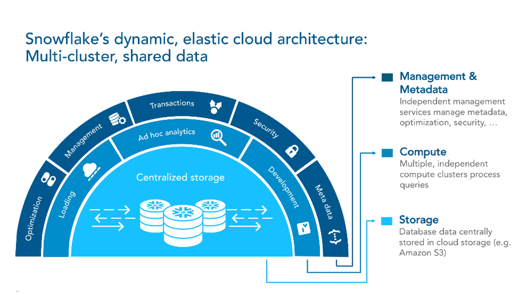
This unique multi-cluster, shared data architecture comprises three distinct layers:
- Storage Layer: handles data storage and is managed by Snowflake. Data is organized in their internal optimized, compressed, columnar format.
- Compute Layer: processes queries using virtual warehouses, which are MPP compute clusters composed of multiple compute nodes allocated by Snowflake. They are independent and do not share compute resources with other virtual warehouses.
- Cloud Services Layer: provides a collection of services that coordinate activities across Snowflake, including authentication, infrastructure management, metadata management, query parsing and optimization, and access control.
All three layers of Snowflake’s architecture are deployed and managed entirely on a selected cloud platform (AWS, GCP or Azure) of your choice within a region.
Snowflake features that will bring a smile to your face
1. Centralized data storage: Snowflake uses a centralized data storage architecture where persisted data is accessible from all compute nodes in the platform. Data is stored in only one place so it can be more effectively managed and accessed.
Centralizing data increases collaboration among teams and ensures that everyone has access to validated, complete data sets, leaving only one source of truth. Ensuring that all current, relevant data is immediately accessible for queries.
2. Elasticity: Snowflake's architecture separates compute and storage, enabling users to scale both resources independently, providing the flexibility to increase or decrease the resources according to different workload scenarios. Users can add or resize nodes instantly, through elastic storage and compute.
And because everything in Snowflake is virtual, this means that we are not physically setting up nodes. We don’t have to provision and install them. This ensures quick and efficient scaling and avoids unnecessary costs.
3. High level of concurrency it provides a high level of concurrency, enabling multiple users to run queries at the same time. This process is called scaling out, using multi-cluster virtual warehouses, which can automatically scale if the number of users and/or queries tends to fluctuate.
It is done by adding more machines to spread out the load. Adding separate warehouses for separate purposes, like production versus ETL versus sandbox, is also an example of scaling out.
4. Load and query performance: it is designed to handle both structured and semi-structured data, and its architecture is optimized for high performance and speed, leveraging multiple virtual warehouses, automatic query optimization, cluster tuning, and micro-partitions for faster query processing.
5. User-friendly UX: its intuitive user interface and SQL-based querying make it easy for users of all skill levels to interact with and analyze data.
6. Security: security is a top priority, with various security measures in place to protect user data. Snowflake encrypts data in transit and at rest, meaning that data is confidential and secure from unauthorized access, both while it's being transferred over the internet and while it's stored on Snowflake's servers.
Regarding control access, Snowflake uses a role-based access control (RBAC) model, where access is granted to specific roles and users are assigned to those roles.
Each role can have its own set of permissions that allow or restrict access to various resources within Snowflake. Snowflake also provides compliance with various regulatory requirements, including SOC 2 Type II, HIPAA, and PCI DSS.
7. Data governance and metadata management: Snowflake's data governance and metadata management features enable users to manage permissions and comply with regulatory requirements. It supports role-based access control as mentioned previously, which allows for granular control over data access.
For metadata management, Snowflake provides two locations for accessing metadata views: the "information_schema" schema available in each database of the Snowflake account, and the "account_usage" schema in the Snowflake database, available in all Snowflake accounts.
8. Backup and recovery support: Snowflake provides automated backup and recovery capabilities (Time Travel and Fail-safe), allowing users to easily revert to a previous state if needed.
Time travel enables accessing historical data at any point within a defined period (retention period depends on the Snowflake edition, for standard edition can be set to 1 day). Fail-safe provides a 7-day period during which historical data may be recoverable by Snowflake.
This period starts immediately after the Time Travel retention period ends. Snowflake also has built-in data replication and disaster recovery capabilities to ensure data availability and reduce the risk of data loss.
If you are looking to take your data game to the next level, Snowflake's got you covered! Whether you're just starting out or you're a big business with complex data demands, Snowflake's flexible and powerful data warehousing solution can help you grow your biz and beat the competition.
So what are you waiting for? Sign up for a Snowflake trial today and get $400 worth of free usage! Need a little help getting started? No problemo! Our team of bright minds is standing by to lend a hand. Just give us a shout and we'll have you up and running in no time!


